参考书籍
- 《SAS编程与数据挖掘商业案例》(预热)
- 「the Little SAS Book」(推荐)
- 「Applied Econometrics Using The SAS System」
SAS编程主要包括DATA和PROC两部分
1 | * create sas data set named toads; |
这样就建立了一个名为toads的临时数据集,然后读入外部文件ToadJump.dat,然后告诉SAS有四个变量,其中第一个是文本型,缺失值用一个点.标记
1 | * Create a SAS data set named sales; |
基本函数
| SAS文本类函数 | |
|---|---|
| ANYALNUM(arg,start) | 返回第一次出现任意数字或字母的位置,可选开始位置start |
| ANYALPHA(arg,start) | 返回第一次出现任意字母的位置,可选开始位置start |
| ANYDIGIT(arg,start) | 返回第一次出现任意数字的位置,可选开始位置start |
| ANYSPACE(arg,start) | 返回第一次出现任意空白的位置,可选开始位置start |
| CAT(arg1,arg2,…argn) | 连接字符串,留下头尾空白 |
| CATS(arg1,arg2,…argn) | 连接字符串,删除头尾空白 |
| CATX(‘separator-string’, arg-1,…,arg-n) | 连接字符串,删除头尾空白并用指定标点连接 |
| COMPRESS(arg, ‘char’) | 移除字符串中的空格和可选字符 |
| INDEX(arg, ‘string’) | 返回指定字符在变量中的位置 |
| LEFT(arg) | 字符串左对齐 |
| LENGTH(arg) | 返回字符串长度,不考虑尾部空格 |
| PROPCASE(arg) | 首字母大写 |
| SUBSTR(arg,position,n) | 从字符串中提取指定开始位置指定长度字符 |
| TRANSLATE(source,to1,from1,…ton,fromn) | 替换字符 |
| TRANWRD(source,from,to) | 替换字符串 |
| TRIM(arg) | 删除尾部空白 |
| UPCASE(arg) | 替换成大写 |
| SAS数值函数 | |
|---|---|
| INT(arg) | 返回整数 |
| LOG(arg) | 自然对数 |
| LOG10(arg) | $10$为底对数 |
| MAX(arg1,arg2,…argn) | 最大值 |
| MEAN(arg1,arg2,…argn) | 均值 |
| MIN(arg1,arg2,…argn) | 最小值 |
| N(arg1,arg2,…argn) | 非缺失值个数 |
| NMISS(arg1,arg2,…argn) | 缺失值个数 |
| ROUND(arg, roundoffunit) | 保留几位小数 |
| SUM(arg1,arg2,…argn) | 求和 |
| SAS日期函数 | |
|---|---|
| DATEJUL(julian-date) | 标准julian日期到SAS日期 |
| DAY(date) | 返回「日」 |
| MDY(month,day,year) | 年月日到SAS日期 |
| MONTH(date) | 返回「月」 |
| QTR(date) | 返回季度 |
| TODAY() | 今日 |
| WEEKDAY(date) | 返回周几(周日为1) |
| YEAR(date) | 返回「年」 |
| YRDIF(start-date,end- date,’ACTUAL’) | 返回相差年份 |
判断结构
1 | * if then structure |
数组操作
1 | * Change all 9 to missing values; |
基本模块调用
搞定基本的函数之后,开始鼓捣$SAS$里面的模型。也就是说,要开始写PROC了。其实,$SAS$比较像$Stata$(计量经济学主流软件),无论是从输出的样式,还是语法。不习惯没有()的模型调用呀。若是说$SAS$和$Stata$的区别,怕只是$Stata$更侧重于计量模型而$SAS$则是服务于大多数统计模型吧。
PROC的基本内容:CONTENT
PROC:content,可以显示数据集的主要特性。比如,
1 | LIBNAME tropical '~/MySASLib'; |
这里主要是两个声明:TITLE和FOOTNOTE。前者输出时候会产生一个标题,后者会产生尾注。用法也是比较直接的:
1 | TITLE ”Here’s another title”; |
SAS PROC求子集:WHERE
如果要在PROC里面先求子集的话,可以直接调用WHERE。感觉这里和$SQL$的思路比较像。
1 | PROC PRINT DATA = '~/desktop/MySASLib/style'; |
SAS PROC 数据进行排序:SORT
1 | DATA marine; |
这样数据就按照Family、Length(递减)排序了。
SAS PROC 输出数据:PRINT
1 | DATA sales; |
SAS PROC里面改变输出格式:FORMAT
基本就是FORMAT一下就可以了,再就是PUT的时候也可以调整。
1 | DATA sales; |
常用的格式有:
- 文本型:
$HEXw.和$w. - 日期型:
DATEw.(输出为ddmmyy或者ddmmyyyy)、DATETIMEw.d(输出为ddmmyy:hh:mm:ss)、DAYw.(输出为dd)、EURDFDDw.、JULIANw.、MMDDYYw.(输出为mmddyy或mmddyyyy)、TIMEw.d(输出为hh:mm:ss)、WEEKDATEw.(输出为工作日)、WORDDATEw.(输出为单词)。 - 数字型:
BESTw.(自动选择)、COMMAw.d(逗号分隔)、DOLLARw.d(货币)、Ew.(科学计数法)、PDw.d、w.d(标准小数)
输出的样本见下:
当然FORMAT还可以自定义factor型变量的输出格式,比如:
1 | DATA carsurvey; |
就可以把数字型的1,2转换为对应的文本male和female等,还可以把变量离散化。
SAS总结数据:MEANS
$SAS$当然还有类似于$Excel$的数据透视表和$R$的data.table的模块,就是MEANS。
可以输出的描述性统计值,包括最大值、最小值、平均值、中位数、余非缺失值个数、缺失值个数、范围、标准差、和等等。此外,还可以使用BY或者CLASS进行分组统计,VAR选择变量等。
1 | DATA sales; |
可以实现
1 | Summary of Flower Sales by Month 1 |
当然这些统计量也可以直接的写入一个SAS数据表,只需要加上一个OUTPUT就可以了。原数据:
1 | 756-01 05/04/2008 120 80 110 |
SAS代码:
1 | DATA sales; |
最终结果为:

SAS PROC统计频率:FREQ
计数的话,就要靠SAS里面的FREQ模块了。比如我们有一个数据集:
1 | esp w cap d cap w kon w ice w kon d esp d kon w ice d esp d |
然后可以用FREQ来统计一些基本量:
1 | DATA orders; |
最终会得到一个$2*5$的表格:
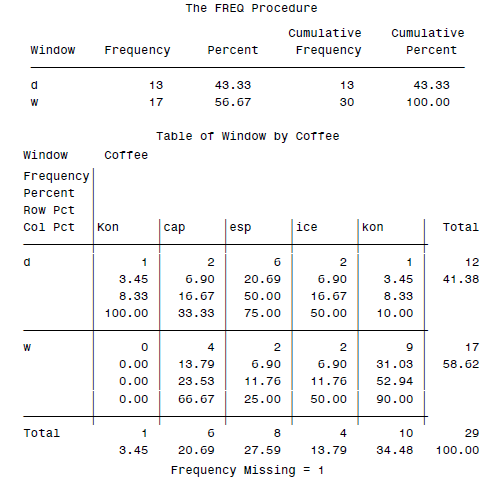
SAS PROC汇报表格:TABULATE
基本看到TABULATE就可以想到那个著名的软件Tabular了…不过貌似SAS也自带了一个类似的表格模块。这个东西可以变得非常复杂,不过鉴于一时半会儿还用不到,没有细细看。抄个例子吧。
原数据:
1 | Silent Lady Maalea sail sch 75.00 |
SAS代码:
1 |
|
最终结果:
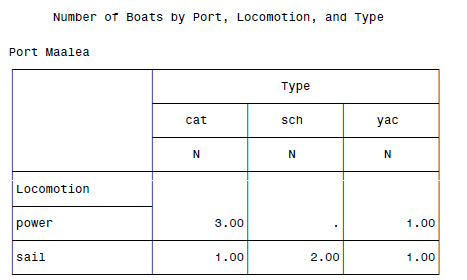
类似的,还可以增加统计量(类似于MEANS那里):
1 | DATA boats; |
可以得到:
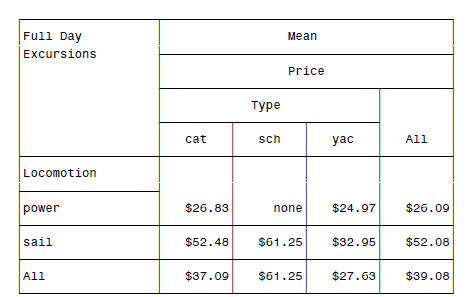
最后还可以混合FORMAT等等,可以变得相当的复杂。貌似这东西是美国劳工部鼓捣出来的格式…
1 | DATA boats; |
BOSS级汇报表格呈现了…
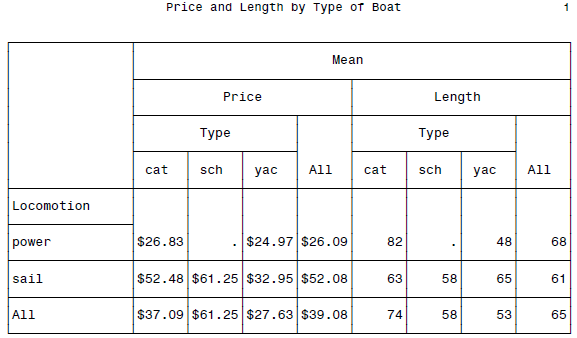
我只能感慨,不愧是商业软件啊,用户需求考虑的真的是特别的周到…这种费时费力做汇报表格的事情也被搞定了,强悍。
SAS里面的报告:REPORT 还有一个REPORT,看到有TABULATE的时候我已经不奇怪并略略的有些期待一个做报告的模块出现了。这东西基本就是前面几个的超级混合体,反正你想搞到的汇报模式总是能够搞出来的。
又是一堆数据:
1 | 17 sci 9 bio 28 fic 50 mys 13 fic 32 fic 67 fic 81 non 38 non |
然后一堆SAS代码:
1 | DATA books; |
然后一堆交叉计数的结果就出来了:
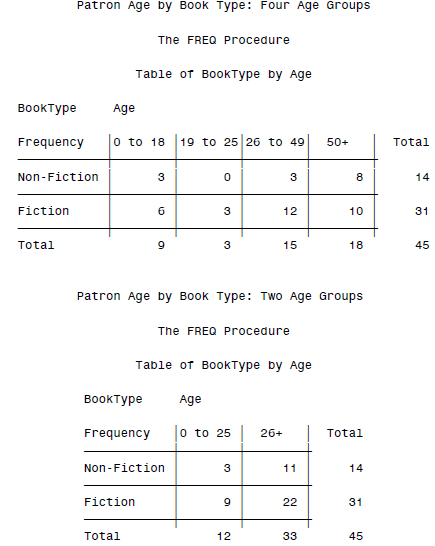
当然,简单的计算和分类统计也不在话下:
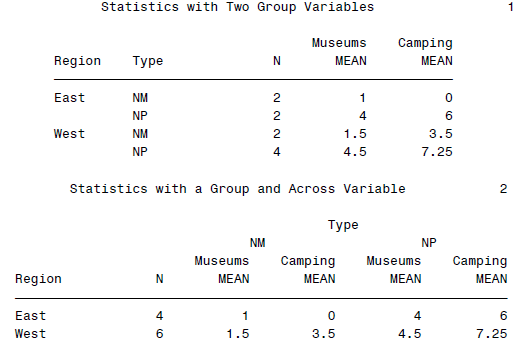
1 | DATA natparks; |
可以得到一个看起来很fancy的表格:
SAS数据总结综述
我的感觉是,MEANS, TABULATE和REPORT这三个模块各有千秋,基本就是可以替代EXCEL的数据透视表,虽然效率上说不好谁比谁高。
