推荐:在线SQL编辑网站
一、数据库基础
- 创建数据库
CREATE DATABASE database_name;
- 查询数据库
show create database <database_name>;
- 删除数据库
drop database <database_name>;
- 修改数据库
alter database <database_name> character set <str_coll> collate <rules>
补充:
- 切换数据库
use db_name;-> 当有多个数据库的情况,需要use db_name;先切换到要操作的数据库 - 查看当前正在使用数据库:
select database();
- 数据表操作:
- 创建数据表
1 | create table table_name( |
- 技巧:复制表结构
1 | create table New_table as |
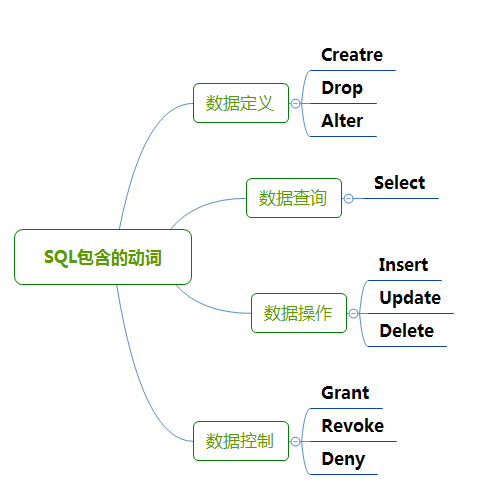
1. SQL功能概述
SQL(Structured Query Language,结构化查询语言)是用户操作关系数据库的通用语言。
基本数据类型
| 数据类型 | 说明 | 存储空间 |
|---|---|---|
| bit | 数据类型是整型,其值只能是0、1或空值。(很省空间的一种数据类型,如果能够满足需求应该尽量多用) | $1$ byte |
| tinyint | 数据类型能存储从$0~255$之间的整数。 | $1$ byte |
| smallint | 数据类型可以存储从$-32768~32767$之间的整数。这种数据类型对存储一些常限定在特定范围内的数值型数据非常有用 | $2$ byte |
| int | 数据类型可以存储从$-2^{31}-2^{31}$之间的整数。存储到数据库的几乎所有数值型的数据都可以用这种数据类型 | $4$ byte |
| numeric(p,s) or decimal(p,s) | 数据类型能用来存储从$-10^{38}-1~10^{38}-1$的固定精度和范围的数值型数据。 | $\leq17$byte |
| char(n) | char数据类型用来存储指定长度的定长非统一编码型的数据,$n$表示字符串的最大长度,取值范围为$1~8000$ (若实际字符串控件小于n,系统自动在后面补空格) | $n$ byte |
| varchar(n) | 可变长度的字符串类型,n表示字符串的最大长度。 | 字符数+2字节额外开销 |
| text | text 数据类型用来存储大量的非统一编码型字符数据。 | 每个字符一个字节 |
| nchar(n) | 用来存储定长统一编码字符型数据。此数据类型能存储4000种字符,使用的字节空间上增加了一倍. | $2n$ byte |
| nvarchar(n) | 数据类型用作变长的统一编码字符型数据。此数据类型能存储4000种字符,使用的字节空间增加了一倍. | 字符数+2字节额外开销 |
| ntext | 可存储$2^{30}-1$个字符 | 每个字符$2$byte |
MySQL5中文参考手册 -> 部分不知道的字段可以通过这个文档查询
二、SQL数据操作语言
1.数据查询语句
1.1 查询语句的基本结构
1 | SELECT <目标列名序列> --需要哪些列 |
SELECT子句用于指定输出的字段
FROM子句用于指定数据的来源
WHERE子句用于指定数据的选择条件
GROUP BY子句用于对检索到的记录进行分组
HAVING 子句用于指定组的选择条件
ORDER BY 子句用于对查询的结果进行排序
1.2 单表查询
- 选择表中列数据
SELECT <column_name[*]> FROM <table_name>
例子 :SELECT Sname,year(getdata()) - year(Birthdate) FROM Student
- 选择表中的若干元祖
- 消除取值相同的行:
DISTINCT
SELECT DISTINCT <val> FROM <table_name>
例子 :SELECT DISTINCT Tom FROM Student
- 查询满足条件的元组
| 查询条件 | 谓 词 |
|---|---|
| 比较 | =、>、>=、<=、<、<>、!=、!>、!< |
| 确定范围 | BETWEy …AND、 NOT BETWEy …AND |
| 确定集合 | IN 、NOT IN |
| 字符匹配 | LIKE 、NOT LIKE |
| 空值 | IS NULL、IS NOT NULL |
| 多重条件(逻辑谓词) | AND、OR |
- 对查询结果进行排序:
将查询结果按照指定的顺序显示。
ASC表示按列值升序排列(从上往下,值从大到小)。DESC表示按列值降序排列(从上往下,值从小到大), 默认为ASC。
ORDER BY <column_name> [ASC|DESC]
例子 :SELECT Sno,Grade FROM SC ORDER BY Grade DESC
1 | -- 用 row_number 排序 |
- 使用聚合函数统计数据: 聚合函数也称为统计函数或集合函数,作用是对一组值进行计算并返回一个统计结果。
| 聚合函数 | 含义 |
|---|---|
| COUNT(*) | 统计表中元组的个数 |
| COUNT([DISTINCT]<column_name>) | 统计本列的非空列值个数 |
| SUM(<column_name>) | 计算列值的和值(必须是数值型列) |
| AVG(<column_name>) | 计算列值的平均值(必须是数值型列) |
| MAX(<column_name>) | 计算列值的最大值 |
| MIN(<column_name>) | 计算列值的最小值 |
1 | --(统计学生总人数) |
注意:聚合函数不能出现在 WHERE 子句中!
- 对数据进行分组统计:
需要先对数据进行分组,然后再对每个组进行统计。分组子句
GROUP BY。在一个查询语句中,可以用多个列进行分组。 分组子句跟在WHERE子句的后面:
1 | GROUP BY <分组依据列>[,...n] |
1.3 多表连接查询
若一个查询同时涉及到两张或以上的表,则称为连接查询。
####1. 内连接: 使用内连接时,如果两个表的相关字段满足条件,则从两个表中提取数据组成新的记录。
FROM <table1> [INNER] JOIN <table2> ON <Join Condition>
注意:连接条件中的连接字段必须是可比的,必须是语义相同的列。
1 | --(查询学生及选课的详细信息) |
补充:
INNER JOIN连接三个表、五个表以上时的SQL语句
- 连接三个数据表,语法格式可以概括为:
FROM (table1 INNER JOIN table2 ON table1.key = table2.key) INNER JOIN table3 ON table1.key = table3.key
- 连接四个数据表,语法格式可以概括为:
FROM ((table1 INNER JOIN table2 ON table1.key=table2.key) INNER JOIN table3 ON table1.key=table3.key) INNER JOIN table4 ON Member.key=table4.key
遵循的规则就是从内而外依次执行
2. 自连接:
自连接是一种特殊的内连接,相互连接的表在物理上是一张表,但在逻辑上可以看做是两张表。
FROM <table1> AS T1 JOIN <table1> AS T2
通过为表取别名的方法,可以让物理上的一张表在逻辑上成为两张表。(一定要为表取别名!)
1 | --(查询与刘晨在同一个系学习的学生的姓名、所在系) |
3. 外连接:
在内连接操作中,只有满足条件的元祖才能出现在查询结果集中。 外连接是只限制一张表中的数据必须满足条件,而另一张表的数据可以不满足条件。
FROM <table1> LEFT|RIGHT [OUTER] JOIN <table2> ON <Join Condition>
1 | LEFT [OUTER] JOIN --称为左外连接,含义是限制表2中的数据必须满足条件,但不管表1中的数据是否满足条件,均输出表1中的数据。 |
2.数据更改功能
2.1 插入数据
INSERT INTO <table_name>[(column_name)] VALUES (val)
(1)简单插入语句
INSERT INTO Student VALUES (‘001’,‘陈东’,‘男’,‘1996/6/23’,‘信息管理系’)
(2)多行插入语句
1 | INSERT INTO SC VALUES('001','C001',90), |
(3)不按表顺序插入语句
按与表列顺序不同的顺序插入数据
INSERT INTO Student(Sno,Sname,Sex,Dept) VALUES ('001','陈东','男','1996/6/23','信息管理系')
2.2 更新数据
UPDATE <table_name> SET column_name = val
(1)无条件更新
UPDATE SC SET Grade = Grade+10
(2)有条件更新
1 | --(将“C001”号课程的学分改成5分) |
2.3 删除数据
DELETE [TOP (expression) [PERCENT]] FROM <table_name>
(1)无条件删除
DELETE FROM Student
(2)有条件删除
1 | --(删除所有考试成绩不合格的学生的选课记录) |
三、高级查询
1. CASE函数
CASE函数是一种多分支函数,它可以根据条件列表的值返回多个可能的结果表达式中的一个。
1.1 简单CASE函数
1 | CASE input_expression |
input_expression:所计算的表达式,可以是一个变量名、字段名、函数或子查询。when_expression:要与input _expression进行比较的简单表达式。简单表达式中不可包含比较运算法,只需给出被比较的表达式或值。else_expression: 比较结果均不为TRUE时返回的表达式。
1 | --(查询选了JAVA课程的学生的学号、姓名、所在系、成绩, |
1.2 搜索CASE函数
简单 CASE函数只能将input_expression与一个单值进行比较,如果需要跟一个范围内的值进行比较,就需要搜索CASE函数。
1 | CASE |
Boolean_expression :比较表达式,可以包含比较运算符,直接将两者进行比较。
1 | -- 上述例子也可以用搜索CASE函数: |
2. 子查询
如果一个SELECT语句嵌套在另一个SELECT、INSERT、UPDATE或DELETE语句中,则称为子查询或内层查询;而包含子查询的语句称为主查询。
1 | SELECT cust_name,cust_contact |
子查询通常用于满足下列需求之一:
- 把一个查询分解成一系列的逻辑步骤
- 提供一个列表作为
WHERE子句和IN、EXISTS、ANY、ALL的目标对象 - 提供由外层查询中每一条记录驱动的查询
子查询通常有几种形式:
WHERE 列名 [NOT] IN (子查询)WHERE 列名 比较运算符 (子查询)WHERE EXISTS(子查询)
四、其他
1. 年月日相关
1 | select |
2. Decode语句
decode(condition,val_1,return_1,val_2,return_2,...,val_n,return_n,default)
可以类比语句理解:
1 | IF condition = val_1 THEN |
3. Use_hash
4. Over() function
常见的分析函数如下:
1 | row_number() over(partition by ... order by ...) |
4. sql * load
SQL*Loader是Oracle提供的用于数据加载的一种工具,它比较适合业务分析类型数据库(数据仓库),能处理多种格式的平面文件,批量数据装载比传统的数据插入效率更高。以sqlldr命令参数执行。
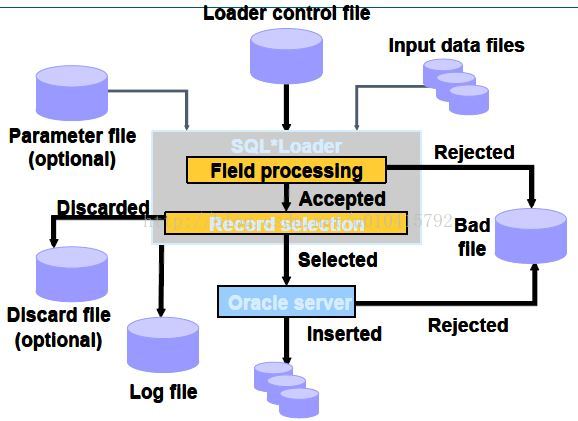
使用sql*loader上传数据,必须指定 控制文件(Control File) (.ctl),
1 | load data |
